 By Kevin Wang On the surface, the workings of the brain appear to be a mystery. Its system of neurons constantly takes in information from our surroundings to somehow produce our thoughts, emotions, and cognition. This process seems unfathomable—even magical. As we look closer, though, a clearer picture begins to form. We can see that each neuron in the brain takes in inputs, or neurotransmitters, from other neurons. Once a sufficient total input is reached, the neuron itself “fires” and produces an output in the form of its own neurotransmitters. While the chemical processes are complex, we can understand and model it with mathematical calculations. Perhaps we could even model it using a computer. The biggest breakthrough in artificial intelligence (AI) came with the idea of modeling the human brain—the best exhibit of natural intelligence. These neural networks are even named after our brain’s system of interconnected neurons. They have found success in emulating human judgment and have even surpassed human accuracy in many trials. They can perform a variety of complex tasks, from recommending products on Amazon to auto-captioning images with great accuracy. The algorithm that makes up this AI has three parts. The input layer takes in outside data that it will interpret. At the end, the output layer at the end produces the intended results. The interesting part, though, is the hidden layer, where the calculations themselves occur. The hidden layer can be made up of many layers in between the input and output layers. These layers work similarly to the way that neurons work in the human brain, where each neuron or cell takes in inputs from other cells and produces an output. A neural network is composed of layers h, which each contain many cells. Every cell in a given layer, say h1, takes inputs from cells in the previous layer, h0. It adjusts all of these inputs by certain weights and then sums up all of these weighted values. The cell then produces its own signal that is taken in by every neuron in the next layer. The important part is in determining the weights assigned to each input, which is how the neural network “learns.” This process occurs by taking a set of training data, that is, data where the desired output is already known. The algorithm then generates a random set of weights and feeds the training data through the neural network. The output will be ridiculously off at first, since the neural network consists of literal random guesses. The algorithm then uses regression, constantly tweaking the weights and comparing the new outputs to the desired one. If it finds success by changing the weights a certain way, it will continue to adjust them. Eventually, the algorithm will arrive at a much more accurate set of weights. 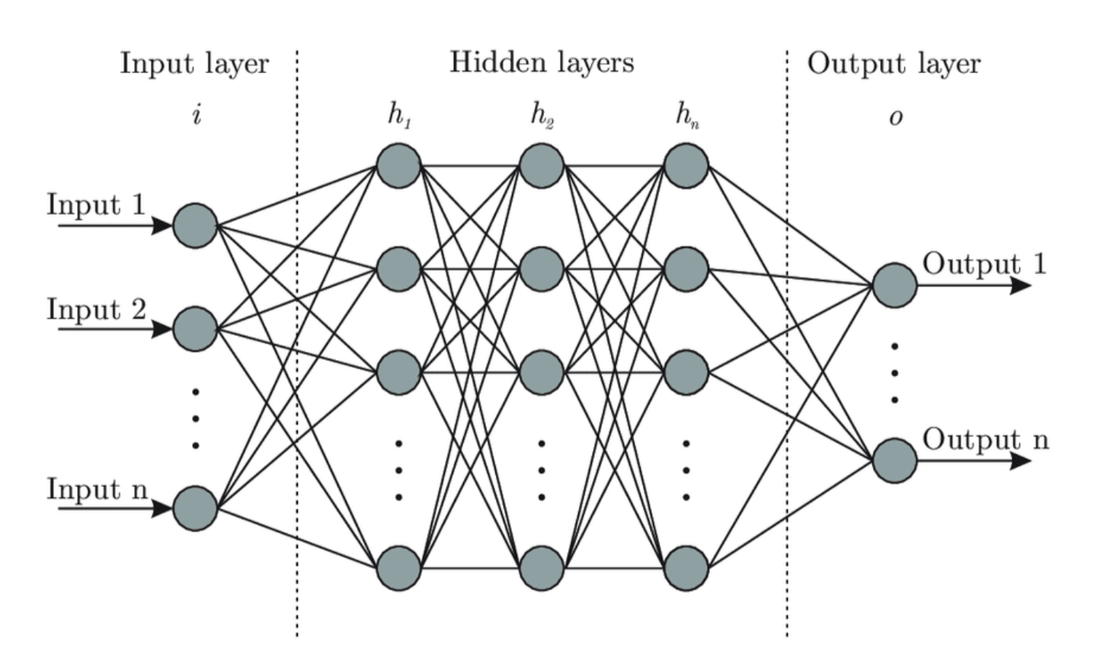 Figure 1: The architecture of a basic neural network. Source: https://www.researchgate.net/figure/Artificial-neural-network-architecture-ANN-i-h-1-h-2-h-n-o_fig1_321259051. While neural networks have found great success, this basic structure is limiting. Because it can only generate a fixed set of weights, it must take in a fixed amount of data each time it is run. This need not be a problem when it comes to images of different sizes and resolutions, as neural networks can pool together data and resize it. The issue arises, though, when it comes to a dataset that is time-dependent—containing images or words in a sequence of unknown time. Consider, for example, a neural network that must analyze a movie. How could it be done? The data is constantly shifting, and involves both the dimension of time and the 2-D images in each frame. One could simply just apply a neural network to every single frame of that movie and produce an output out of it. This is not how our brain works, though, since it would fail to capture the defining feature of how the movie works: its plot. For, while each frame of a movie communicates information, it does not function independently. The information that we determine from each frame depends on each of the frames before it, that is, what has been leading up to the present. To take a smaller example, imagine a baseball being thrown from a pitcher to a batter. In any given frame in the middle, a neural network may be able to tell that the ball is midair. However, it cannot tell from that single frame if the ball is moving from the pitcher to the batter, from the batter to the pitcher, or if it is simply hovering in midair. It needs the context of surrounding frames to determine that the ball is moving in a certain direction. This is where recurrent neural networks, or RNNs, come in. RNNs function much like generic neural networks, with an input, a hidden layer, and an output. The difference comes in the fact that the hidden layer has much more flexibility. Consider the movie example again. Each frame of the movie will be fed through the RNN, producing information. But each time this happens, the hidden layer will produce two outputs: one that determines the information produced from that frame, and one that becomes an input for the next layer. This is how RNNs are able to create time dependency and determine context. Let’s take a look at how this operates mathematically. Each frame xi of the movie is an input to an iteration, or run-through of the neural network. Each iteration ti has a hidden layer that will produce an output, yi. This output indicates what happened in that frame. It also produces a separate output hi ( different from the hi referenced earlier) that could contain information such as which characters are onscreen and their current positions. This will serve as an additional input to the next iteration. The next iteration ti+1 will take in inputs from both its frame xi+1 and the output hi from the last iteration. As a result, it is able to use information from both its own frame and from earlier frames. 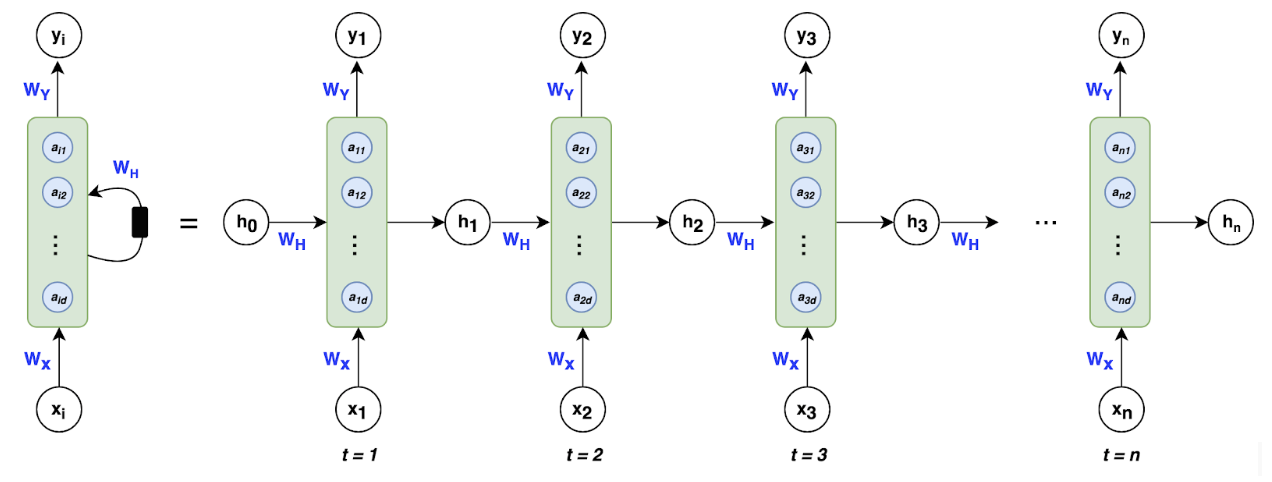 Figure 2: The recurrent neural network. The name comes from the fact that each hidden layer feeds the next, then repeats the process. Source: https://medium.com/towards-artificial-intelligence/whirlwind-tour-of-rnns-a11effb7808f. This is a step towards solving the problem of time dependency, but it has a few problems. Firstly, it is still too rigid. The way the hi outputs are produced must be predetermined, and there is no way to change this process for specific iterations. The type of information conveyed, such as which characters are on-screen, will be the same throughout the entire movie. Therefore, the algorithm treats every frame identically, which may not be optimal. For example, we may want to prioritize the information of characters in some frames and inanimate objects in others. This limitation has a secondary effect, where the algorithm has a hard time connecting frames as they get farther apart. If two frames have many iterations between them, much of the information from the first frame will be lost by the time the algorithm gets to the second. A symbol or object that is shown in the opening moments of the movie may reappear at the end, but the algorithm may have forgotten about it by then. However, new technologies are being developed that build upon RNNs that can address these issues. Long Short Term Memory networks, or LSTMs, are able to selectively retain certain types of information for different lengths of time. Micro-level information, such as the positions of characters onscreen, may only be used for the duration of a certain scene. Macro-level plot information, on the other hand, may be kept throughout the entire movie. By building on the technology of RNNs, researchers have found ways to solve its weaknesses. Ultimately, RNNs have been a crucial development in AI, allowing it much more flexibility and bringing us closer to the way the human brain actually works. They have found use with temporal data, such as text analysis, voice software, video analysis, and other data files involving time. As we continue to use them, we will surely find new ways to expand upon their function and create even more flexible, powerful technologies.
0 Comments
Leave a Reply. |