 Illustration by Zoe Heidenry By Kevin Wang The COVID-19 pandemic forced school districts to shift to online learning, and with this transition came an increased reliance on technology. Zoom and Google Meet have been effective platforms for communication, and developers have offered creative ways for teachers to provide personalized attention to students. Some of these include machine learning software to track students’ progress and automatically assign specific homework problems. Other technologies, however, have been far more daring—for example, algorithms that can grade students’ essays. From Red Pen to the Essay Autograder “Essay autograders” have actually been around for quite a while, starting from 1997 with Thomas Landauer and Peter Foltz’s Latent Semantic Analysis (LSA). With new artificial intelligence (AI) developments in recent years, these technologies have become far more advanced. The concept seems troubling, though: while multiple choice questions and math problems have one objective answer, essays are inherently subjective and complex. Different readers have different evaluations and even interpretations of an essay. How could a machine possibly reduce the nuances of a personally-written essay to a single, objective score? To begin, let’s discuss the basics of these algorithms. Automated essay-graders are a form of Natural Language Processing (NLP), the field of machine learning that deals with data in the form of language. Individual words can have many meanings and connotations depending on their context, though. In contrast to numerical data, it is difficult to define the exact relationships between words. In response to this challenge, developers have used a technique called word vectoring, or converting words and sentences into vectors. These vectors, just like those in physics, have both a magnitude and a direction and can even be plotted on a graph. As such, they’re easy for computers to manipulate and perform calculations with. Turning Words into Numbers The core of word vectoring involves representing each word as the sum of other words in a system’s vocabulary. For example, suppose our vocabulary consisted of the words “man,” woman,” and “royalty.” We can represent a word by assigning weights from 0-1 for each of these vocabulary words based on how closely related the words are. Therefore, “king” would have very high weights for “male” and “royalty,” and a weight of nearly 0 for “female.” These weights are determined using various forms of regression, where the weights are first assigned randomly, then tweaked as data is fed into the system. This process concludes when the algorithm achieves the series of weights that most accurately predicts the chosen word. We can then add together all of the vocabulary word vectors, scaling each vector according to its weight. This produces a total vector for every word from the sum of its vocabulary. Word vectoring is useful because it gives us a mathematical representation of each word, and actually “understands” the relationship between words. We can convert words into other words by literally adding and subtracting them. “King” - “male” + “female” = “queen.” “Paris” - “France” = “Beijing - “China” = “Capital.” In reality, this space has at least thousands of vocabulary words with hundreds of dimensions for the vectors. However, the concept remains the same, and word vectoring allows machines to understand words with impressive accuracy. 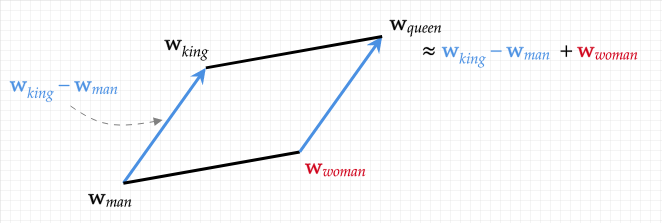 An example of words represented as vectors. Source: https://www.ed.ac.uk/informatics/news-events/stories/2019/king-man-woman-queen-the-hidden-algebraic-struct Grading the Essay
Once these vectors are created, it is possible to begin analyzing the essay. This process happens in two ways. First, the essay is given an overall vector, which can be as simple as averaging all of the vectors of the words in the essay, or analyzing the frequency of certain “keywords” related to the prompt. This provides facts about the essay, such word count, average word length, and complexity of vocabulary. The next process involves analyzing the flow and progression of the text. This is done by looking at different parts of the essay in relation to each other by using a long short term memory neural network (LSTM). The LSTM keeps a memory of each phrase in the essay, but continuously “throws out” some of the information as it gets farther along into the essay. Thus, earlier sequences diminish in importance as the algorithm “reads” through the essay, allowing the program to follow and evaluate the writer’s train of thought. Does the Algorithm Pass? Comparisons with human graders reveal that the scores generated by these machines are fairly accurate, with up to 94% accuracy in some trials. Nevertheless, this system has its flaws. Firstly, it seems difficult to assign an objective score when even human readers can assign very different scores to the same essay. Whose metric is the “right” way to score an essay? Furthermore, experiments with these algorithms indicate that there are certain ways to “cheat the system” by using bigger words such as “avarice” instead of “greed,” including complicated words such as “however” and “despite,” and even just writing a longer essay. There are certainly correlations between these characteristics and writing ability, but their mere presence does not necessitate a strong essay or writer. In fact, such a grading system punishes unconventional, creative approaches, since it is based off of many conventional, average essays. Despite this, automated essay graders have become increasingly prevalent, from individual teachers grading their students to states using them for standardized tests [8]. They surely would save countless hours of reading—but for now, it might be best to stick with traditional grading methods.
0 Comments
Leave a Reply. |